from dsc80_utils import *
Agenda 📆¶
- Text features.
- Bag of words.
- Cosine similarity.
- TF-IDF.
- Example: State of the Union addresses 🎤.
Question 🤔 (Answer at dsc80.com/q)
Code: weird_re
^\w{2,5}.\d*\/[^A-Z5]{1,}
Select all strings below that contain any match with the regular expression above.
"billy4/Za""billy4/za""DAI_s2154/pacific""daisy/ZZZZZ""bi_/_lly98""!@__!14/atlantic"
(This problem was from Sp22 Final question 7.2.)
Text features¶

Review: Regression and features¶
- In DSC 40A, our running example was to use regression to predict a data scientist's salary, given their GPA, years of experience, and years of education.
- After minimizing empirical risk to determine optimal parameters, $w_0^*, \dots, w_3^*$, we made predictions using:
$$\text{predicted salary} = w_0^* + w_1^* \cdot \text{GPA} + w_2^* \cdot \text{experience} + w_3^* \cdot \text{education}$$
- GPA, years of experience, and years of education are features – they represent a data scientist as a vector of numbers.
- e.g. Your feature vector may be [3.5, 1, 7].
- This approach requires features to be numeric.
Moving forward¶
Suppose we'd like to predict the sentiment of a piece of text from 1 to 10.
- 10: Very positive (happy).
- 1: Very negative (sad, angry).
Example:
Input: "DSC 80 is a pretty good class."
Output: 7.
We can frame this as a regression problem, but we can't directly use what we learned in 40A, because here our inputs are text, not numbers.
Text features¶
- Big question: How do we represent a text document as a feature vector of numbers?
- If we can do this, we can:
- use a text document as input in a regression or classification model (in a few lectures).
- quantify the similarity of two text documents (today).
Example: San Diego employee salaries¶
- Transparent California publishes the salaries of all City of San Diego employees.
- Let's look at the 2022 data.
salaries = pd.read_csv('https://transcal.s3.amazonaws.com/public/export/san-diego-2022.csv')
salaries['Employee Name'] = salaries['Employee Name'].str.split().str[0] + ' Xxxx'
salaries.head()
| Employee Name | Job Title | Base Pay | Overtime Pay | ... | Year | Notes | Agency | Status | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Mara Xxxx | City Attorney | 227441.53 | 0.00 | ... | 2022 | NaN | San Diego | FT |
| 1 | Todd Xxxx | Mayor | 227441.53 | 0.00 | ... | 2022 | NaN | San Diego | FT |
| 2 | Terence Xxxx | Assistant Police Chief | 227224.32 | 0.00 | ... | 2022 | NaN | San Diego | FT |
| 3 | Esmeralda Xxxx | Police Sergeant | 124604.40 | 162506.54 | ... | 2022 | NaN | San Diego | FT |
| 4 | Marcelle Xxxx | Assistant Retirement Administrator | 279868.04 | 0.00 | ... | 2022 | NaN | San Diego | FT |
5 rows × 13 columns
Aside on privacy and ethics¶
- Even though the data we downloaded is publicly available, employee names still correspond to real people.
- Be careful when dealing with PII (personably identifiable information).
- Only work with the data that is needed for your analysis.
- Even when data is public, people have a reasonable right to privacy.
- Remember to think about the impacts of your work outside of your Jupyter Notebook.
Goal: Quantifying similarity¶
- Our goal is to describe, numerically, how similar two job titles are.
- For instance, our similarity metric should tell us that
'Deputy Fire Chief'and'Fire Battalion Chief'are more similar than'Deputy Fire Chief'and'City Attorney'.
- Idea: Two job titles are similar if they contain shared words, regardless of order. So, to measure the similarity between two job titles, we could count the number of words they share in common.
- Before we do this, we need to be confident that the job titles are clean and consistent – let's explore.
Exploring job titles¶
jobtitles = salaries['Job Title']
jobtitles.head()
0 City Attorney 1 Mayor 2 Assistant Police Chief 3 Police Sergeant 4 Assistant Retirement Administrator Name: Job Title, dtype: object
How many employees are in the dataset? How many unique job titles are there?
jobtitles.shape[0], jobtitles.nunique()
(12831, 611)
What are the most common job titles?
jobtitles.value_counts().iloc[:10]
Job Title
Police Officer Ii 1082
Police Sergeant 311
Fire Fighter Ii 306
...
Associate Engineer - Civil 254
Fire Captain 225
Program Manager 216
Name: count, Length: 10, dtype: int64
Are there any missing job titles?
jobtitles.isna().sum()
np.int64(0)
Fortunately, no.
Canonicalization¶
Remember, our goal is ultimately to count the number of shared words between job titles. But before we start counting the number of shared words, we need to consider the following:
- Some job titles may have punctuation, like
'-'and'&', which may count as words when they shouldn't.'Assistant - Manager'and'Assistant Manager'should count as the same job title.
- Some job titles may have "glue" words, like
'to'and'the', which (we can argue) also shouldn't count as words.'Assistant To The Manager'and'Assistant Manager'should count as the same job title.
- If we just want to focus on the titles themselves, then perhaps roman numerals should be removed: that is,
'Police Officer Ii'and'Police Officer I'should count as the same job title.
Let's address the above issues. The process of converting job titles so that they are always represented the same way is called canonicalization.
Punctuation¶
Are there job titles with unnecessary punctuation that we can remove?
To find out, we can write a regular expression that looks for characters other than letters, numbers, and spaces.
We can use regular expressions with the
.strmethods we learned earlier in the quarter just by usingregex=True.
# Uses character class negation.
jobtitles.str.contains(r'[^A-Za-z0-9 ]', regex=True).sum()
np.int64(922)
jobtitles[jobtitles.str.contains(r'[^A-Za-z0-9 ]', regex=True)].head()
137 Park & Recreation Director 248 Associate Engineer - Mechanical 734 Associate Engineer - Electrical 882 Associate Engineer - Traffic 1045 Associate Engineer - Civil Name: Job Title, dtype: object
It seems like we should replace these pieces of punctuation with a single space.
"Glue" words¶
Are there job titles with "glue" words in the middle, such as 'Assistant to the Manager'?
To figure out if any titles contain the word 'to', we can't just do the following, because it will evaluate to True for job titles that have 'to' anywhere in them, even if not as a standalone word.
# Why are we converting to lowercase?
jobtitles.str.lower().str.contains('to').sum()
np.int64(1577)
jobtitles[jobtitles.str.lower().str.contains(' to ')]
1638 Assistant To The Chief Operating Officer
2183 Principal Assistant To City Attorney
2238 Assistant To The Director
...
6594 Confidential Secretary To Chief Operating Officer
6832 Confidential Secretary To Mayor
11028 Confidential Secretary To Mayor
Name: Job Title, Length: 10, dtype: object
Instead, we need to look for 'to' separated by word boundaries.
jobtitles.str.lower().str.contains(r'\bto\b', regex=True).sum()
np.int64(10)
jobtitles[jobtitles.str.lower().str.contains(r'\bto\b', regex=True)]
1638 Assistant To The Chief Operating Officer
2183 Principal Assistant To City Attorney
2238 Assistant To The Director
...
6594 Confidential Secretary To Chief Operating Officer
6832 Confidential Secretary To Mayor
11028 Confidential Secretary To Mayor
Name: Job Title, Length: 10, dtype: object
We can look for other filler words too, like 'the' and 'for'.
jobtitles[jobtitles.str.lower().str.contains(r'\bthe\b', regex=True)]
1638 Assistant To The Chief Operating Officer 2238 Assistant To The Director 5609 Assistant To The Director 6544 Assistant To The Director Name: Job Title, dtype: object
jobtitles[jobtitles.str.lower().str.contains(r'\bfor\b', regex=True)]
3449 Assistant For Community Outreach 6889 Assistant For Community Outreach 10810 Assistant For Community Outreach Name: Job Title, dtype: object
We should probably remove these "glue" words.
Roman numerals (e.g. "Ii")¶
Lastly, let's try and identify job titles that have roman numerals at the end, like 'i' (1), 'ii' (2), 'iii' (3), or 'iv' (4). As before, we'll convert to lowercase first.
jobtitles[jobtitles.str.lower().str.contains(r'\bi+v?\b', regex=True)]
5 Police Officer Ii
10 Police Officer Ii
48 Fire Prevention Inspector Ii
...
12822 Clerical Assistant Ii
12828 Police Officer Ii
12830 Police Officer I
Name: Job Title, Length: 6087, dtype: object
Let's get rid of those numbers, too.
Fixing punctuation and removing "glue" words and roman numerals¶
Let's put the preceeding three steps together and canonicalize job titles by:
- converting to lowercase,
- removing each occurrence of
'to','the', and'for', - replacing each non-letter/digit/space character with a space,
- replacing each sequence of roman numerals – either
'i','ii','iii', or'iv'at the end with nothing, and - replacing each sequence of multiple spaces with a single space.
jobtitles = (
jobtitles
.str.lower()
.str.replace(r'\bto\b|\bthe\b\|bfor\b', '', regex=True)
.str.replace(r'[^A-Za-z0-9 ]', ' ', regex=True)
.str.replace(r'\bi+v?\b', '', regex=True)
.str.replace(r' +', ' ', regex=True) # ' +' matches 1 or more occurrences of a space.
.str.strip() # Removes leading/trailing spaces if present.
)
jobtitles.sample(5)
262 police sergeant 8658 police records clerk 6613 plant technician 352 fire captain 7860 collections investigator supervisor Name: Job Title, dtype: object
(jobtitles == 'police officer').sum()
np.int64(1378)
Bag of words 💰¶
Text similarity¶
Recall, our idea is to measure the similarity of two job titles by counting the number of shared words between the job titles. How do we actually do that, for all of the job titles we have?
A counts matrix¶
Let's create a "counts" matrix, such that:
- there is 1 row per job title,
- there is 1 column per unique word that is used in job titles, and
- the value in row
titleand columnwordis the number of occurrences ofwordintitle.
Such a matrix might look like:
| senior | lecturer | teaching | professor | assistant | associate | |
|---|---|---|---|---|---|---|
| senior lecturer | 1 | 1 | 0 | 0 | 0 | 0 |
| assistant teaching professor | 0 | 0 | 1 | 1 | 1 | 0 |
| associate professor | 0 | 0 | 0 | 1 | 0 | 1 |
| senior assistant to the assistant professor | 1 | 0 | 0 | 1 | 2 | 0 |
Then, we can make statements like: "assistant teaching professor" is more similar to "associate professor" than to "senior lecturer".
Creating a counts matrix¶
First, we need to determine all words that are used across all job titles.
jobtitles.str.split()
0 [city, attorney]
1 [mayor]
2 [assistant, police, chief]
...
12828 [police, officer]
12829 [police, dispatcher]
12830 [police, officer]
Name: Job Title, Length: 12831, dtype: object
# The .explode method concats the lists together.
all_words = jobtitles.str.split().explode()
all_words
0 city
0 attorney
1 mayor
...
12829 dispatcher
12830 police
12830 officer
Name: Job Title, Length: 30064, dtype: object
Next, to determine the columns of our matrix, we need to find a list of all unique words used in titles. We can do this with np.unique, but value_counts shows us the distribution, which is interesting.
unique_words = all_words.value_counts()
unique_words
Job Title
police 2299
officer 1608
assistant 1267
...
gardener 1
governmental 1
dna 1
Name: count, Length: 332, dtype: int64
Note that in unique_words.index, job titles are sorted by number of occurrences!
For each of the 330 unique words that are used in job titles, we can count the number of occurrences of the word in each job title.
'deputy fire chief'contains the word'deputy'once, the word'fire'once, and the word'chief'once.'assistant managers assistant'contains the word'assistant'twice and the word'managers'once.
# Created using a dictionary to avoid a "DataFrame is highly fragmented" warning.
counts_dict = {}
for word in unique_words.index:
re_pat = fr'\b{word}\b'
counts_dict[word] = jobtitles.str.count(re_pat).astype(int).tolist()
counts_df = pd.DataFrame(counts_dict).set_index(jobtitles)
counts_df.head()
| police | officer | assistant | fire | ... | stores | gardener | governmental | dna | |
|---|---|---|---|---|---|---|---|---|---|
| Job Title | |||||||||
| city attorney | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 |
| mayor | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 |
| assistant police chief | 1 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 |
| police sergeant | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 |
| assistant retirement administrator | 0 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 |
5 rows × 332 columns
counts_df.shape
(12831, 332)
counts_df has one row for all 12831 employees, and one column for each unique word that is used in a job title.
Its third row, for example, tells us that the third job title contains 'police' once and 'assistant' once.
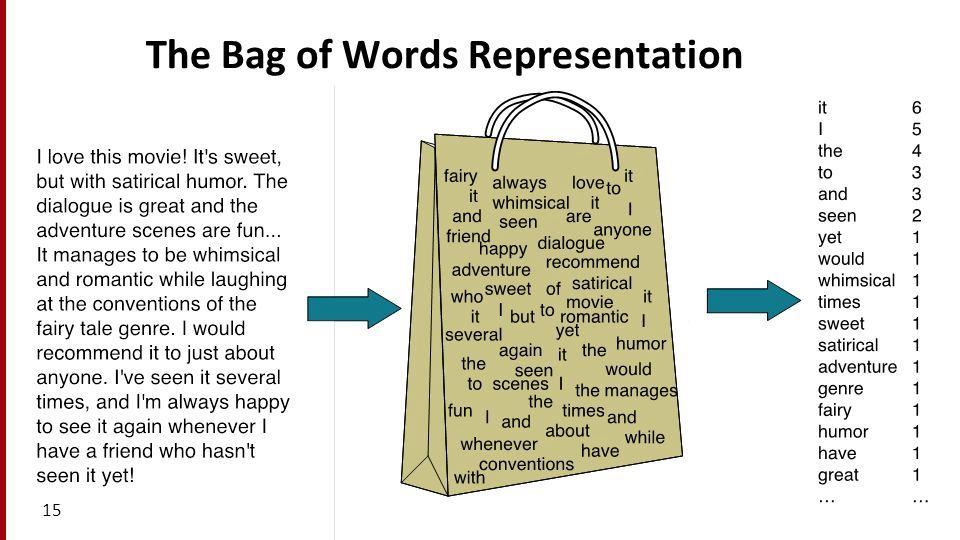
Bag of words¶
- The bag of words model represents texts (e.g. job titles, sentences, documents) as vectors of word counts.
- The "counts" matrices we have worked with so far were created using the bag of words model.
- The bag of words model defines a vector space in $\mathbb{R}^{\text{number of unique words}}$.
- In the matrix on the previous slide, each row was a vector corresponding to a specific job title.
- It is called "bag of words" because it doesn't consider order.
{kind=link}
Cosine similarity¶
Question: What job titles are most similar to 'deputy fire chief'?¶
- Remember, our idea was to count the number of shared words between two job titles.
- We now have access to
counts_df, which contains a row vector for each job title.
- How can we use it to count the number of shared words between two job titles?
Counting shared words¶
To start, let's compare the row vectors for 'deputy fire chief' and 'fire battalion chief'.
dfc = counts_df.loc['deputy fire chief'].iloc[0]
dfc
police 0
officer 0
assistant 0
..
gardener 0
governmental 0
dna 0
Name: deputy fire chief, Length: 332, dtype: int64
fbc = counts_df.loc['fire battalion chief'].iloc[0]
fbc
police 0
officer 0
assistant 0
..
gardener 0
governmental 0
dna 0
Name: fire battalion chief, Length: 332, dtype: int64
We can stack these two vectors horizontally.
pair_counts = (
pd.concat([dfc, fbc], axis=1)
.sort_values(by=['deputy fire chief', 'fire battalion chief'], ascending=False)
.head(10)
.T
)
pair_counts
| fire | chief | deputy | battalion | ... | assistant | engineer | civil | technician | |
|---|---|---|---|---|---|---|---|---|---|
| deputy fire chief | 1 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 0 |
| fire battalion chief | 1 | 1 | 0 | 1 | ... | 0 | 0 | 0 | 0 |
2 rows × 10 columns
'deputy fire chief' and 'fire battalion chief' have 2 shared words in common. One way to arrive at this result mathematically is by taking their dot product:
np.dot(pair_counts.iloc[0], pair_counts.iloc[1])
np.int64(2)
Recall: The dot product¶
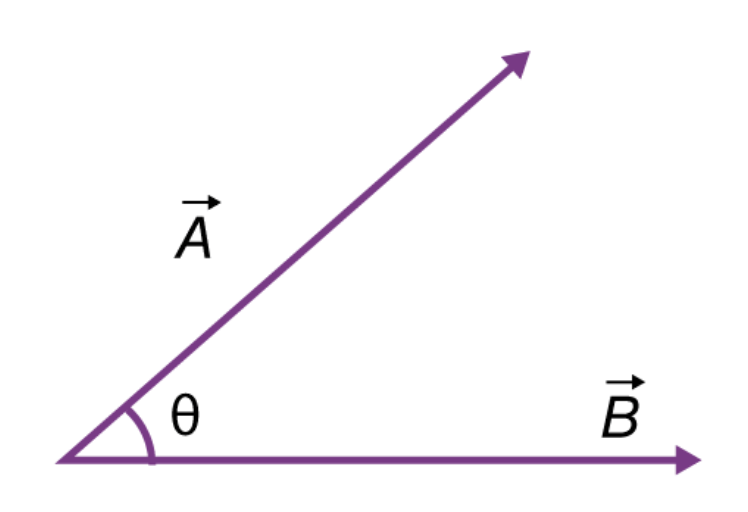
- Recall, if $\vec{a} = \begin{bmatrix} a_1 & a_2 & ... & a_n \end{bmatrix}^T$ and $\vec{b} = \begin{bmatrix} b_1 & b_2 & ... & b_n \end{bmatrix}^T$ are two vectors, then their dot product $\vec{a} \cdot \vec{b}$ is defined as:
$$\vec{a} \cdot \vec{b} = a_1b_1 + a_2b_2 + ... + a_nb_n$$
- The dot product also has a geometric interpretation. If $|\vec{a}|$ and $|\vec{b}|$ are the $L_2$ norms (lengths) of $\vec{a}$ and $\vec{b}$, and $\theta$ is the angle between $\vec{a}$ and $\vec{b}$, then:
$$\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos \theta$$
 (source)
(source)- $\cos \theta$ is equal to its maximum value (1) when $\theta = 0$, i.e. when $\vec{a}$ and $\vec{b}$ point in the same direction.
Cosine similarity and bag of words¶
To measure the similarity between two word vectors, instead of just counting the number of shared words, we should compute their normalized dot product, also known as their cosine similarity.
$$\cos \theta = \boxed{\frac{\vec{a} \cdot \vec{b}}{|\vec{a}| | \vec{b}|}}$$
- If all elements in $\vec{a}$ and $\vec{b}$ are non-negative, then $\cos \theta$ ranges from 0 to 1.
- 🚨 Key idea: The larger $\cos \theta$ is, the more similar the two vectors are!
- It is important to normalize by the lengths of the vectors, otherwise texts with more words will have artificially high similarities with other texts.
Normalizing¶
$$\cos \theta = \boxed{\frac{\vec{a} \cdot \vec{b}}{|\vec{a}| | \vec{b}|}}$$
- Why can't we just use the dot product – that is, why must we divide by $|\vec{a}| | \vec{b}|$?
- Consider the following example:
| big | data | science | |
|---|---|---|---|
| big big big big data | 4 | 1 | 0 |
| big data science | 1 | 1 | 1 |
| science big data | 1 | 1 | 1 |
| Pair | Dot Product | Cosine Similarity |
|---|---|---|
| big data science and big big big big data | 5 | 0.7001 |
| big data science and science big data | 3 | 1 |
'big big big big data'has a large dot product with'big data science'just because it has the word'big'four times. But intuitively,'big data science'and'science big data'should be as similar as possible, since they're permutations of the same sentence.
- So, make sure to compute the cosine similarity – don't just use the dot product!
Note: Sometimes, you will see the cosine distance being used. It is the complement of cosine similarity:
$$\text{dist}(\vec{a}, \vec{b}) = 1 - \cos \theta$$
If $\text{dist}(\vec{a}, \vec{b})$ is small, the two word vectors are similar.
A recipe for computing similarities¶
Given a set of documents, to find the most similar text to one document $d$ in particular:
- Use the bag of words model to create a counts matrix, in which:
- there is 1 row per document,
- there is 1 column per unique word that is used across documents, and
- the value in row
docand columnwordis the number of occurrences ofwordindoc.
- Compute the cosine similarity between $d$'s row vector and all other documents' row vectors.
- The other document with the greatest cosine similarity is the most similar, under the bag of words model.
Example: Global warming 🌎¶
Consider the following three documents.
sentences = pd.Series([
'I really really want global peace',
'I must enjoy global warming',
'We must solve climate change'
])
sentences
0 I really really want global peace 1 I must enjoy global warming 2 We must solve climate change dtype: object
Let's represent each document using the bag of words model.
unique_words = sentences.str.split().explode().value_counts()
unique_words
I 2
really 2
global 2
..
solve 1
climate 1
change 1
Name: count, Length: 12, dtype: int64
counts_dict = {}
for word in unique_words.index:
re_pat = fr'\b{word}\b'
counts_dict[word] = sentences.str.count(re_pat).astype(int).tolist()
counts_df = pd.DataFrame(counts_dict).set_index(sentences)
counts_df
| I | really | global | must | ... | We | solve | climate | change | |
|---|---|---|---|---|---|---|---|---|---|
| I really really want global peace | 1 | 2 | 1 | 0 | ... | 0 | 0 | 0 | 0 |
| I must enjoy global warming | 1 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 |
| We must solve climate change | 0 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 1 |
3 rows × 12 columns
Let's now find the cosine similarity between each document.
counts_df
| I | really | global | must | ... | We | solve | climate | change | |
|---|---|---|---|---|---|---|---|---|---|
| I really really want global peace | 1 | 2 | 1 | 0 | ... | 0 | 0 | 0 | 0 |
| I must enjoy global warming | 1 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 |
| We must solve climate change | 0 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 1 |
3 rows × 12 columns
def sim_pair(s1, s2):
return np.dot(s1, s2) / (np.linalg.norm(s1) * np.linalg.norm(s2))
# Look at the documentation of the .corr method to see how this works!
counts_df.T.corr(sim_pair)
| I really really want global peace | I must enjoy global warming | We must solve climate change | |
|---|---|---|---|
| I really really want global peace | 1.00 | 0.32 | 0.0 |
| I must enjoy global warming | 0.32 | 1.00 | 0.2 |
| We must solve climate change | 0.00 | 0.20 | 1.0 |
Issue: Bag of words only encodes the words that each document uses, not their meanings.
- "I really really want global peace" and "We must solve climate change" have similar meanings, but have no shared words, and thus a low cosine similarity.
- "I really really want global peace" and "I must enjoy global warming" have very different meanings, but a relatively high cosine similarity.
Pitfalls of the bag of words model¶
Remember, the key assumption underlying the bag of words model is that two documents are similar if they share many words in common.
- The bag of words model doesn't consider order.
- The job titles
'deputy fire chief'and'chief fire deputy'are treated as the same.
- The job titles
- The bag of words model doesn't consider the meaning of words.
'I love data science'and'I hate data science'share 75% of their words, but have very different meanings.
- The bag of words model treats all words as being equally important.
'deputy'and'fire'have the same importance, even though'fire'is probably more important in describing someone's job title.- Let's address this point.
Question 🤔 (Answer at dsc80.com/q)
Code: bow
From the Fa23 final: Consider the following corpus:
Document number Content
1 yesterday rainy today sunny
2 yesterday sunny today sunny
3 today rainy yesterday today
4 yesterday yesterday today today
- Using a bag-of-words representation, which two documents have the largest dot product?
- Using a bag-of-words representation, what is the cosine similarity between documents 2 and 3?
TF-IDF¶
The importance of words¶
Issue: The bag of words model doesn't know which words are "important" in a document. Consider the following document:
How do we determine which words are important?
- The most common words ("the", "has") often don't have much meaning!
- The very rare words are also less important!
Goal: Find a way of quantifying the importance of a word in a document by balancing the above two factors, i.e. find the word that best summarizes a document.
Term frequency¶
- The term frequency of a word (term) $t$ in a document $d$, denoted $\text{tf}(t, d)$ is the proportion of words in document $d$ that are equal to $t$.
$$ \text{tf}(t, d)= \frac{\text{\# of occurrences of $t$ in $d$}}{\text{total \# of words in $d$}} $$
- Example: What is the term frequency of "billy" in the following document?
- Answer: $\frac{2}{13}$.
- Intuition: Words that occur often within a document are important to the document's meaning.
- If $\text{tf}(t, d)$ is large, then word $t$ occurs often in $d$.
- If $\text{tf}(t, d)$ is small, then word $t$ does not occur often $d$.
- Issue: "has" also has a TF of $\frac{2}{13}$, but it seems less important than "billy".
Inverse document frequency¶
- The inverse document frequency of a word $t$ in a set of documents $d_1, d_2, ...$ is
$$\text{idf}(t) = \log \left(\frac{\text{total \# of documents}}{\text{\# of documents in which $t$ appears}} \right)$$
- Example: What is the inverse document frequency of "billy" in the following three documents?
- "my brother has a friend named billy who has an uncle named billy"
- "my favorite artist is named jilly boel"
- "why does he talk about someone named billy so often"
- Answer: $\log \left(\frac{3}{2}\right) \approx 0.4055$.
- Intuition: If a word appears in every document (like "the" or "has"), it is probably not a good summary of any one document.
- If $\text{idf}(t)$ is large, then $t$ is rarely found in documents.
- If $\text{idf}(t)$ is small, then $t$ is commonly found in documents.
- Think of $\text{idf}(t)$ as the "rarity factor" of $t$ across documents – the larger $\text{idf}(t)$ is, the more rare $t$ is.
Intuition¶
$$\text{tf}(t, d) = \frac{\text{\# of occurrences of $t$ in $d$}}{\text{total \# of words in $d$}}$$
$$\text{idf}(t) = \log \left(\frac{\text{total \# of documents}}{\text{\# of documents in which $t$ appears}} \right)$$
Goal: Quantify how well word $t$ summarizes document $d$.
- If $\text{tf}(t, d)$ is small, then $t$ doesn't occur very often in $d$, so $t$ can't be a good summary of $d$.
- If $\text{idf}(t)$ is small, then $t$ occurs often amongst all documents, and so it is not a good summary of any one document.
- If $\text{tf}(t, d)$ and $\text{idf}(t)$ are both large, then $t$ occurs often in $d$ but rarely overall. This makes $t$ a good summary of document $d$.
Term frequency-inverse document frequency¶
The term frequency-inverse document frequency (TF-IDF) of word $t$ in document $d$ is the product:
$$ \begin{align*} \text{tfidf}(t, d) &= \text{tf}(t, d) \cdot \text{idf}(t) \\\ &= \frac{\text{\# of occurrences of $t$ in $d$}}{\text{total \# of words in $d$}} \cdot \log \left(\frac{\text{total \# of documents}}{\text{\# of documents in which $t$ appears}} \right) \end{align*} $$
- If $\text{tfidf}(t, d)$ is large, then $t$ is a good summary of $d$, because $t$ occurs often in $d$ but rarely across all documents.
- TF-IDF is a heuristic – it has no probabilistic justification.
- To know if $\text{tfidf}(t, d)$ is large for one particular word $t$, we need to compare it to $\text{tfidf}(t_i, d)$, for several different words $t_i$.
Computing TF-IDF¶
Question: What is the TF-IDF of "global" in the second sentence?
sentences
0 I really really want global peace 1 I must enjoy global warming 2 We must solve climate change dtype: object
Answer:
tf = sentences.iloc[1].count('global') / len(sentences.iloc[1].split())
tf
0.2
idf = np.log(len(sentences) / sentences.str.contains('global').sum())
idf
np.float64(0.4054651081081644)
tf * idf
np.float64(0.08109302162163289)
Question: Is this big or small? Is "global" the best summary of the second sentence?
TF-IDF of all words in all documents¶
On its own, the TF-IDF of a word in a document doesn't really tell us anything; we must compare it to TF-IDFs of other words in that same document.
sentences
0 I really really want global peace 1 I must enjoy global warming 2 We must solve climate change dtype: object
unique_words = np.unique(sentences.str.split().explode())
unique_words
array(['I', 'We', 'change', 'climate', 'enjoy', 'global', 'must', 'peace',
'really', 'solve', 'want', 'warming'], dtype=object)
tfidf_dict = {}
for word in unique_words:
re_pat = fr'\b{word}\b'
tf = sentences.str.count(re_pat) / sentences.str.split().str.len()
idf = np.log(len(sentences) / sentences.str.contains(re_pat).sum())
tfidf_dict[word] = tf * idf
tfidf = pd.DataFrame(tfidf_dict).set_index(sentences)
tfidf
| I | We | change | climate | ... | really | solve | want | warming | |
|---|---|---|---|---|---|---|---|---|---|
| I really really want global peace | 0.07 | 0.00 | 0.00 | 0.00 | ... | 0.37 | 0.00 | 0.18 | 0.00 |
| I must enjoy global warming | 0.08 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.22 |
| We must solve climate change | 0.00 | 0.22 | 0.22 | 0.22 | ... | 0.00 | 0.22 | 0.00 | 0.00 |
3 rows × 12 columns
Interpreting TF-IDFs¶
display_df(tfidf, cols=12)
| I | We | change | climate | enjoy | global | must | peace | really | solve | want | warming | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I really really want global peace | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.18 | 0.37 | 0.00 | 0.18 | 0.00 |
| I must enjoy global warming | 0.08 | 0.00 | 0.00 | 0.00 | 0.22 | 0.08 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.22 |
| We must solve climate change | 0.00 | 0.22 | 0.22 | 0.22 | 0.00 | 0.00 | 0.08 | 0.00 | 0.00 | 0.22 | 0.00 | 0.00 |
The above DataFrame tells us that:
- the TF-IDF of
'really'in the first sentence is $\approx$ 0.37, - the TF-IDF of
'climate'in the second sentence is 0.
Note that there are two ways that $\text{tfidf}(t, d) = \text{tf}(t, d) \cdot \text{idf}(t)$ can be 0:
- If $t$ appears in every document, because then $\text{idf}(t) = \log (\frac{\text{\# documents}}{\text{\# documents}}) = \log(1) = 0$.
- If $t$ does not appear in document $d$, because then $\text{tf}(t, d) = \frac{0}{\text{len}(d)} = 0$.
The word that best summarizes a document is the word with the highest TF-IDF for that document:
display_df(tfidf, cols=12)
| I | We | change | climate | enjoy | global | must | peace | really | solve | want | warming | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I really really want global peace | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.18 | 0.37 | 0.00 | 0.18 | 0.00 |
| I must enjoy global warming | 0.08 | 0.00 | 0.00 | 0.00 | 0.22 | 0.08 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.22 |
| We must solve climate change | 0.00 | 0.22 | 0.22 | 0.22 | 0.00 | 0.00 | 0.08 | 0.00 | 0.00 | 0.22 | 0.00 | 0.00 |
tfidf.idxmax(axis=1)
I really really want global peace really I must enjoy global warming enjoy We must solve climate change We dtype: object
Look closely at the rows of tfidf – in documents 2 and 3, the max TF-IDF is not unique!
Example: State of the Union addresses 🎤¶
State of the Union addresses¶
The 2024 State of the Union address was delivered on March 7th, 2024; last year's was on February 7th, 2023.
from IPython.display import YouTubeVideo
YouTubeVideo('gzcBTUvVp7M')
The data¶
from pathlib import Path
sotu_txt = Path('data') / 'stateoftheunion1790-2023.txt'
sotu = sotu_txt.read_text()
len(sotu)
10577941
The entire corpus (another word for "set of documents") is over 10 million characters long... let's not display it in our notebook.
print(sotu[:1600])
The Project Gutenberg EBook of Complete State of the Union Addresses, from 1790 to the Present. Speeches beginning in 2002 are from UCSB The American Presidency Project. Speeches from 2018-2023 were manually downloaded from whitehouse.gov. Character set encoding: UTF8 The addresses are separated by three asterisks CONTENTS George Washington, State of the Union Address, January 8, 1790 George Washington, State of the Union Address, December 8, 1790 George Washington, State of the Union Address, October 25, 1791 George Washington, State of the Union Address, November 6, 1792 George Washington, State of the Union Address, December 3, 1793 George Washington, State of the Union Address, November 19, 1794 George Washington, State of the Union Address, December 8, 1795 George Washington, State of the Union Address, December 7, 1796 John Adams, State of the Union Address, November 22, 1797 John Adams, State of the Union Address, December 8, 1798 John Adams, State of the Union Address, December 3, 1799 John Adams, State of the Union Address, November 11, 1800 Thomas Jefferson, State of the Union Address, December 8, 1801 Thomas Jefferson, State of the Union Address, December 15, 1802 Thomas Jefferson, State of the Union Address, October 17, 1803 Thomas Jefferson, State of the Union Address, November 8, 1804 Thomas Jefferson, State of the Union Address, December 3, 1805 Thomas Jefferson, State of the Union Address, December 2, 1806 Thomas Jefferson, State of the Union Address, October 27, 1807 Thomas Jefferson, State of the Union Address,
Each speech is separated by '***'.
speeches = sotu.split('\n***\n')[1:]
len(speeches)
233
Note that each "speech" currently contains other information, like the name of the president and the date of the address.
print(speeches[-1][:1000])
State of the Union Address Joseph R. Biden Jr. February 7, 2023 Mr. Speaker. Madam Vice President. Our First Lady and Second Gentleman. Members of Congress and the Cabinet. Leaders of our military. Mr. Chief Justice, Associate Justices, and retired Justices of the Supreme Court. And you, my fellow Americans. I start tonight by congratulating the members of the 118th Congress and the new Speaker of the House, Kevin McCarthy. Mr. Speaker, I look forward to working together. I also want to congratulate the new leader of the House Democrats and the first Black House Minority Leader in history, Hakeem Jeffries. Congratulations to the longest serving Senate leader in history, Mitch McConnell. And congratulations to Chuck Schumer for another term as Senate Majority Leader, this time with an even bigger majority. And I want to give special recognition to someone who I think will be considered the greatest Speaker in the history of this country, Nancy Pelosi. The story of Amer
Let's extract just the speech text.
import re
def extract_struct(speech):
L = speech.strip().split('\n', maxsplit=3)
L[3] = re.sub(r"[^A-Za-z' ]", ' ', L[3]).lower()
return dict(zip(['speech', 'president', 'date', 'contents'], L))
speeches_df = pd.DataFrame(list(map(extract_struct, speeches)))
speeches_df
| speech | president | date | contents | |
|---|---|---|---|---|
| 0 | State of the Union Address | George Washington | January 8, 1790 | fellow citizens of the senate and house of re... |
| 1 | State of the Union Address | George Washington | December 8, 1790 | fellow citizens of the senate and house of re... |
| 2 | State of the Union Address | George Washington | October 25, 1791 | fellow citizens of the senate and house of re... |
| ... | ... | ... | ... | ... |
| 230 | State of the Union Address | Joseph R. Biden Jr. | April 28, 2021 | thank you thank you thank you good to be b... |
| 231 | State of the Union Address | Joseph R. Biden Jr. | March 1, 2022 | madam speaker madam vice president and our ... |
| 232 | State of the Union Address | Joseph R. Biden Jr. | February 7, 2023 | mr speaker madam vice president our firs... |
233 rows × 4 columns
Finding the most important words in each speech¶
Here, a "document" is a speech. We have 233 documents.
speeches_df
| speech | president | date | contents | |
|---|---|---|---|---|
| 0 | State of the Union Address | George Washington | January 8, 1790 | fellow citizens of the senate and house of re... |
| 1 | State of the Union Address | George Washington | December 8, 1790 | fellow citizens of the senate and house of re... |
| 2 | State of the Union Address | George Washington | October 25, 1791 | fellow citizens of the senate and house of re... |
| ... | ... | ... | ... | ... |
| 230 | State of the Union Address | Joseph R. Biden Jr. | April 28, 2021 | thank you thank you thank you good to be b... |
| 231 | State of the Union Address | Joseph R. Biden Jr. | March 1, 2022 | madam speaker madam vice president and our ... |
| 232 | State of the Union Address | Joseph R. Biden Jr. | February 7, 2023 | mr speaker madam vice president our firs... |
233 rows × 4 columns
A rough sketch of what we'll compute:
for each word t:
for each speech d:
compute tfidf(t, d)
unique_words = speeches_df['contents'].str.split().explode().value_counts()
# Take the top 500 most common words for speed
unique_words = unique_words.iloc[:500].index
unique_words
Index(['the', 'of', 'to', 'and', 'in', 'a', 'that', 'for', 'be', 'our',
...
'desire', 'call', 'submitted', 'increasing', 'months', 'point', 'trust',
'throughout', 'set', 'object'],
dtype='object', name='contents', length=500)
💡 Pro-Tip: Using tqdm¶
This code takes a while to run, so we'll use the tdqm package to track its progress. (Install with mamba install tqdm if needed).
from tqdm.notebook import tqdm
tfidf_dict = {}
tf_denom = speeches_df['contents'].str.split().str.len()
# Wrap the sequence with `tqdm()` to display a progress bar
for word in tqdm(unique_words):
re_pat = fr' {word} ' # Imperfect pattern for speed.
tf = speeches_df['contents'].str.count(re_pat) / tf_denom
idf = np.log(len(speeches_df) / speeches_df['contents'].str.contains(re_pat).sum())
tfidf_dict[word] = tf * idf
0%| | 0/500 [00:00<?, ?it/s]
tfidf = pd.DataFrame(tfidf_dict)
tfidf.head()
| the | of | to | and | ... | trust | throughout | set | object | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 4.29e-04 | 0.00e+00 | 0.00e+00 | 2.04e-03 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.06e-03 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 4.06e-04 | 0.00e+00 | 3.48e-04 | 6.44e-04 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 6.70e-04 | 2.17e-04 | 0.00e+00 | 7.09e-04 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 2.38e-04 | 4.62e-04 | 0.00e+00 | 3.77e-04 |
5 rows × 500 columns
Note that the TF-IDFs of many common words are all 0!
Summarizing speeches¶
By using idxmax, we can find the word with the highest TF-IDF in each speech.
summaries = tfidf.idxmax(axis=1)
summaries
0 object
1 convention
2 provision
...
230 it's
231 tonight
232 it's
Length: 233, dtype: object
What if we want to see the 5 words with the highest TF-IDFs, for each speech?
def five_largest(row):
return ', '.join(row.index[row.argsort()][-5:])
keywords = tfidf.apply(five_largest, axis=1)
keywords_df = pd.concat([
speeches_df['president'],
speeches_df['date'],
keywords
], axis=1)
keywords_df
| president | date | 0 | |
|---|---|---|---|
| 0 | George Washington | January 8, 1790 | your, proper, regard, ought, object |
| 1 | George Washington | December 8, 1790 | case, established, object, commerce, convention |
| 2 | George Washington | October 25, 1791 | community, upon, lands, proper, provision |
| ... | ... | ... | ... |
| 230 | Joseph R. Biden Jr. | April 28, 2021 | get, americans, percent, jobs, it's |
| 231 | Joseph R. Biden Jr. | March 1, 2022 | let, jobs, americans, get, tonight |
| 232 | Joseph R. Biden Jr. | February 7, 2023 | down, percent, jobs, tonight, it's |
233 rows × 3 columns
Uncomment the cell below to see every single row of keywords_df.
display_df(keywords_df, rows=233)
| president | date | 0 | |
|---|---|---|---|
| 0 | George Washington | January 8, 1790 | your, proper, regard, ought, object |
| 1 | George Washington | December 8, 1790 | case, established, object, commerce, convention |
| 2 | George Washington | October 25, 1791 | community, upon, lands, proper, provision |
| 3 | George Washington | November 6, 1792 | subject, upon, information, proper, provision |
| 4 | George Washington | December 3, 1793 | having, vessels, executive, shall, ought |
| 5 | George Washington | November 19, 1794 | too, army, let, ought, constitution |
| 6 | George Washington | December 8, 1795 | army, prevent, object, provision, treaty |
| 7 | George Washington | December 7, 1796 | republic, treaty, britain, ought, object |
| 8 | John Adams | November 22, 1797 | spain, british, claims, treaty, vessels |
| 9 | John Adams | December 8, 1798 | st, minister, treaty, spain, commerce |
| 10 | John Adams | December 3, 1799 | civil, period, british, minister, treaty |
| 11 | John Adams | November 11, 1800 | experience, protection, navy, commerce, ought |
| 12 | Thomas Jefferson | December 8, 1801 | consideration, shall, object, vessels, subject |
| 13 | Thomas Jefferson | December 15, 1802 | shall, debt, naval, duties, vessels |
| 14 | Thomas Jefferson | October 17, 1803 | debt, vessels, sum, millions, friendly |
| 15 | Thomas Jefferson | November 8, 1804 | received, convention, having, due, friendly |
| 16 | Thomas Jefferson | December 3, 1805 | families, convention, sum, millions, vessels |
| 17 | Thomas Jefferson | December 2, 1806 | due, consideration, millions, shall, spain |
| 18 | Thomas Jefferson | October 27, 1807 | whether, army, british, vessels, shall |
| 19 | Thomas Jefferson | November 8, 1808 | thus, british, millions, commerce, her |
| 20 | James Madison | November 29, 1809 | cases, having, due, british, minister |
| 21 | James Madison | December 5, 1810 | provisions, view, minister, commerce, british |
| 22 | James Madison | November 5, 1811 | britain, provisions, commerce, minister, british |
| 23 | James Madison | November 4, 1812 | nor, subject, provisions, britain, british |
| 24 | James Madison | December 7, 1813 | number, having, naval, britain, british |
| 25 | James Madison | September 20, 1814 | naval, vessels, britain, his, british |
| 26 | James Madison | December 5, 1815 | debt, treasury, millions, establishment, sum |
| 27 | James Madison | December 3, 1816 | constitution, annual, sum, treasury, british |
| 28 | James Monroe | December 12, 1817 | improvement, territory, indian, millions, lands |
| 29 | James Monroe | November 16, 1818 | minister, object, territory, her, spain |
| 30 | James Monroe | December 7, 1819 | parties, friendly, minister, treaty, spain |
| 31 | James Monroe | November 14, 1820 | amount, minister, extent, vessels, spain |
| 32 | James Monroe | December 3, 1821 | powers, duties, revenue, spain, vessels |
| 33 | James Monroe | December 3, 1822 | object, proper, vessels, spain, convention |
| 34 | James Monroe | December 2, 1823 | th, department, object, minister, spain |
| 35 | James Monroe | December 7, 1824 | spain, governments, convention, parties, object |
| 36 | John Quincy Adams | December 6, 1825 | officers, commerce, condition, upon, improvement |
| 37 | John Quincy Adams | December 5, 1826 | commercial, upon, vessels, british, duties |
| 38 | John Quincy Adams | December 4, 1827 | lands, british, receipts, upon, th |
| 39 | John Quincy Adams | December 2, 1828 | duties, revenue, upon, commercial, britain |
| 40 | Andrew Jackson | December 8, 1829 | attention, subject, her, upon, duties |
| 41 | Andrew Jackson | December 6, 1830 | general, subject, character, vessels, upon |
| 42 | Andrew Jackson | December 6, 1831 | indian, commerce, claims, treaty, minister |
| 43 | Andrew Jackson | December 4, 1832 | general, subject, duties, lands, commerce |
| 44 | Andrew Jackson | December 3, 1833 | treasury, convention, minister, spain, duties |
| 45 | Andrew Jackson | December 1, 1834 | bill, treaty, minister, claims, upon |
| 46 | Andrew Jackson | December 7, 1835 | treaty, upon, claims, subject, minister |
| 47 | Andrew Jackson | December 5, 1836 | upon, treasury, duties, revenue, banks |
| 48 | Martin van Buren | December 5, 1837 | price, subject, upon, banks, lands |
| 49 | Martin van Buren | December 3, 1838 | subject, upon, indian, banks, court |
| 50 | Martin van Buren | December 2, 1839 | duties, treasury, extent, institutions, banks |
| 51 | Martin van Buren | December 5, 1840 | general, revenue, upon, extent, having |
| 52 | John Tyler | December 7, 1841 | banks, britain, amount, duties, treasury |
| 53 | John Tyler | December 6, 1842 | claims, minister, thus, amount, treasury |
| 54 | John Tyler | December 6, 1843 | treasury, british, her, minister, mexico |
| 55 | John Tyler | December 3, 1844 | minister, upon, treaty, her, mexico |
| 56 | James Polk | December 2, 1845 | british, convention, territory, duties, mexico |
| 57 | James Polk | December 8, 1846 | army, territory, minister, her, mexico |
| 58 | James Polk | December 7, 1847 | amount, treaty, her, army, mexico |
| 59 | James Polk | December 5, 1848 | tariff, upon, bill, constitution, mexico |
| 60 | Zachary Taylor | December 4, 1849 | territory, treaty, recommend, minister, mexico |
| 61 | Millard Fillmore | December 2, 1850 | recommend, claims, upon, mexico, duties |
| 62 | Millard Fillmore | December 2, 1851 | department, annual, fiscal, subject, mexico |
| 63 | Millard Fillmore | December 6, 1852 | duties, navy, mexico, subject, her |
| 64 | Franklin Pierce | December 5, 1853 | commercial, regard, upon, construction, subject |
| 65 | Franklin Pierce | December 4, 1854 | character, duties, naval, minister, property |
| 66 | Franklin Pierce | December 31, 1855 | constitution, british, territory, convention, ... |
| 67 | Franklin Pierce | December 2, 1856 | institutions, property, condition, thus, terri... |
| 68 | James Buchanan | December 8, 1857 | treaty, constitution, territory, convention, b... |
| 69 | James Buchanan | December 6, 1858 | june, mexico, minister, constitution, territory |
| 70 | James Buchanan | December 19, 1859 | minister, th, fiscal, mexico, june |
| 71 | James Buchanan | December 3, 1860 | minister, duties, claims, convention, constitu... |
| 72 | Abraham Lincoln | December 3, 1861 | army, claims, labor, capital, court |
| 73 | Abraham Lincoln | December 1, 1862 | upon, population, shall, per, sum |
| 74 | Abraham Lincoln | December 8, 1863 | upon, receipts, subject, navy, naval |
| 75 | Abraham Lincoln | December 6, 1864 | condition, secretary, naval, treasury, navy |
| 76 | Andrew Johnson | December 4, 1865 | form, commerce, powers, general, constitution |
| 77 | Andrew Johnson | December 3, 1866 | thus, june, constitution, mexico, condition |
| 78 | Andrew Johnson | December 3, 1867 | june, value, department, upon, constitution |
| 79 | Andrew Johnson | December 9, 1868 | millions, amount, expenditures, june, per |
| 80 | Ulysses S. Grant | December 6, 1869 | subject, upon, receipts, per, spain |
| 81 | Ulysses S. Grant | December 5, 1870 | her, convention, vessels, spain, british |
| 82 | Ulysses S. Grant | December 4, 1871 | object, powers, treaty, desire, recommend |
| 83 | Ulysses S. Grant | December 2, 1872 | territory, line, her, britain, treaty |
| 84 | Ulysses S. Grant | December 1, 1873 | consideration, banks, subject, amount, claims |
| 85 | Ulysses S. Grant | December 7, 1874 | duties, upon, attention, claims, convention |
| 86 | Ulysses S. Grant | December 7, 1875 | parties, territory, court, spain, claims |
| 87 | Ulysses S. Grant | December 5, 1876 | subject, court, per, commission, claims |
| 88 | Rutherford B. Hayes | December 3, 1877 | upon, sum, fiscal, commercial, value |
| 89 | Rutherford B. Hayes | December 2, 1878 | per, secretary, fiscal, june, indian |
| 90 | Rutherford B. Hayes | December 1, 1879 | subject, territory, june, commission, indian |
| 91 | Rutherford B. Hayes | December 6, 1880 | subject, office, relations, attention, commercial |
| 92 | Chester A. Arthur | December 6, 1881 | spain, international, british, relations, frie... |
| 93 | Chester A. Arthur | December 4, 1882 | territory, establishment, mexico, internationa... |
| 94 | Chester A. Arthur | December 4, 1883 | total, convention, mexico, commission, treaty |
| 95 | Chester A. Arthur | December 1, 1884 | treaty, territory, commercial, secretary, vessels |
| 96 | Grover Cleveland | December 8, 1885 | duties, vessels, treaty, condition, upon |
| 97 | Grover Cleveland | December 6, 1886 | mexico, claims, subject, convention, fiscal |
| 98 | Grover Cleveland | December 6, 1887 | condition, sum, thus, price, tariff |
| 99 | Grover Cleveland | December 3, 1888 | secretary, treaty, upon, per, june |
| 100 | Benjamin Harrison | December 3, 1889 | general, commission, indian, upon, lands |
| 101 | Benjamin Harrison | December 1, 1890 | receipts, subject, upon, per, tariff |
| 102 | Benjamin Harrison | December 9, 1891 | court, tariff, indian, upon, per |
| 103 | Benjamin Harrison | December 6, 1892 | tariff, secretary, upon, value, per |
| 104 | William McKinley | December 6, 1897 | conditions, upon, international, territory, spain |
| 105 | William McKinley | December 5, 1898 | navy, commission, naval, june, spain |
| 106 | William McKinley | December 5, 1899 | treaty, officers, commission, international, c... |
| 107 | William McKinley | December 3, 1900 | settlement, civil, shall, convention, commission |
| 108 | Theodore Roosevelt | December 3, 1901 | army, commercial, conditions, navy, man |
| 109 | Theodore Roosevelt | December 2, 1902 | upon, man, navy, conditions, tariff |
| 110 | Theodore Roosevelt | December 7, 1903 | june, lands, territory, property, treaty |
| 111 | Theodore Roosevelt | December 6, 1904 | cases, conditions, indian, labor, man |
| 112 | Theodore Roosevelt | December 5, 1905 | upon, conditions, commission, cannot, man |
| 113 | Theodore Roosevelt | December 3, 1906 | upon, navy, tax, court, man |
| 114 | Theodore Roosevelt | December 3, 1907 | conditions, navy, upon, army, man |
| 115 | Theodore Roosevelt | December 8, 1908 | man, officers, labor, control, banks |
| 116 | William H. Taft | December 7, 1909 | convention, banks, court, department, tariff |
| 117 | William H. Taft | December 6, 1910 | department, court, commercial, international, ... |
| 118 | William H. Taft | December 5, 1911 | mexico, department, per, tariff, court |
| 119 | William H. Taft | December 3, 1912 | tariff, upon, army, per, department |
| 120 | Woodrow Wilson | December 2, 1913 | how, shall, upon, mexico, ought |
| 121 | Woodrow Wilson | December 8, 1914 | shall, convention, ought, matter, upon |
| 122 | Woodrow Wilson | December 7, 1915 | her, navy, millions, economic, cannot |
| 123 | Woodrow Wilson | December 5, 1916 | commerce, shall, upon, commission, bill |
| 124 | Woodrow Wilson | December 4, 1917 | purpose, her, know, settlement, shall |
| 125 | Woodrow Wilson | December 2, 1918 | shall, go, men, upon, back |
| 126 | Woodrow Wilson | December 2, 1919 | economic, her, budget, labor, conditions |
| 127 | Woodrow Wilson | December 7, 1920 | expenditures, receipts, treasury, budget, upon |
| 128 | Warren Harding | December 6, 1921 | capital, ought, problems, conditions, tariff |
| 129 | Warren Harding | December 8, 1922 | responsibility, republic, problems, ought, per |
| 130 | Calvin Coolidge | December 6, 1923 | conditions, production, commission, ought, court |
| 131 | Calvin Coolidge | December 3, 1924 | navy, international, desire, economic, court |
| 132 | Calvin Coolidge | December 8, 1925 | international, budget, economic, ought, court |
| 133 | Calvin Coolidge | December 7, 1926 | tax, federal, reduction, tariff, ought |
| 134 | Calvin Coolidge | December 6, 1927 | construction, banks, per, program, property |
| 135 | Calvin Coolidge | December 4, 1928 | federal, department, production, program, per |
| 136 | Herbert Hoover | December 3, 1929 | commission, federal, construction, tariff, per |
| 137 | Herbert Hoover | December 2, 1930 | about, budget, economic, per, construction |
| 138 | Herbert Hoover | December 8, 1931 | upon, construction, federal, economic, banks |
| 139 | Herbert Hoover | December 6, 1932 | health, june, value, economic, banks |
| 140 | Franklin D. Roosevelt | January 3, 1934 | labor, permanent, problems, cannot, banks |
| 141 | Franklin D. Roosevelt | January 4, 1935 | private, work, local, program, cannot |
| 142 | Franklin D. Roosevelt | January 3, 1936 | income, shall, let, say, today |
| 143 | Franklin D. Roosevelt | January 6, 1937 | powers, convention, needs, help, problems |
| 144 | Franklin D. Roosevelt | January 3, 1938 | budget, business, economic, today, income |
| 145 | Franklin D. Roosevelt | January 4, 1939 | labor, cannot, capital, income, billion |
| 146 | Franklin D. Roosevelt | January 3, 1940 | world, domestic, cannot, economic, today |
| 147 | Franklin D. Roosevelt | January 6, 1941 | freedom, problems, cannot, program, today |
| 148 | Franklin D. Roosevelt | January 6, 1942 | him, today, know, forces, production |
| 149 | Franklin D. Roosevelt | January 7, 1943 | pacific, get, cannot, americans, production |
| 150 | Franklin D. Roosevelt | January 11, 1944 | individual, total, know, economic, cannot |
| 151 | Franklin D. Roosevelt | January 6, 1945 | cannot, production, army, forces, jobs |
| 152 | Harry S. Truman | January 21, 1946 | fiscal, program, billion, million, dollars |
| 153 | Harry S. Truman | January 6, 1947 | commission, budget, economic, labor, program |
| 154 | Harry S. Truman | January 7, 1948 | tax, billion, today, program, economic |
| 155 | Harry S. Truman | January 5, 1949 | economic, price, program, cannot, production |
| 156 | Harry S. Truman | January 4, 1950 | income, today, program, programs, economic |
| 157 | Harry S. Truman | January 8, 1951 | help, program, production, strength, economic |
| 158 | Harry S. Truman | January 9, 1952 | defense, working, program, help, production |
| 159 | Harry S. Truman | January 7, 1953 | republic, free, cannot, world, economic |
| 160 | Dwight D. Eisenhower | February 2, 1953 | federal, labor, budget, economic, programs |
| 161 | Dwight D. Eisenhower | January 7, 1954 | federal, programs, economic, budget, program |
| 162 | Dwight D. Eisenhower | January 6, 1955 | problems, federal, economic, programs, program |
| 163 | Dwight D. Eisenhower | January 5, 1956 | billion, federal, problems, economic, program |
| 164 | Dwight D. Eisenhower | January 10, 1957 | cannot, programs, human, program, economic |
| 165 | Dwight D. Eisenhower | January 9, 1958 | program, strength, today, programs, economic |
| 166 | Dwight D. Eisenhower | January 9, 1959 | growth, help, billion, programs, economic |
| 167 | Dwight D. Eisenhower | January 7, 1960 | freedom, cannot, today, economic, help |
| 168 | Dwight D. Eisenhower | January 12, 1961 | million, percent, billion, program, programs |
| 169 | John F. Kennedy | January 30, 1961 | budget, programs, problems, economic, program |
| 170 | John F. Kennedy | January 11, 1962 | billion, help, program, jobs, cannot |
| 171 | John F. Kennedy | January 14, 1963 | help, cannot, tax, percent, billion |
| 172 | Lyndon B. Johnson | January 8, 1964 | help, billion, americans, budget, million |
| 173 | Lyndon B. Johnson | January 4, 1965 | americans, man, programs, tonight, help |
| 174 | Lyndon B. Johnson | January 12, 1966 | program, percent, help, billion, tonight |
| 175 | Lyndon B. Johnson | January 10, 1967 | programs, americans, billion, tonight, percent |
| 176 | Lyndon B. Johnson | January 17, 1968 | programs, million, budget, tonight, billion |
| 177 | Lyndon B. Johnson | January 14, 1969 | americans, program, billion, budget, tonight |
| 178 | Richard Nixon | January 22, 1970 | billion, percent, america, today, programs |
| 179 | Richard Nixon | January 22, 1971 | federal, americans, budget, tonight, let |
| 180 | Richard Nixon | January 20, 1972 | america, program, programs, today, help |
| 181 | Richard Nixon | February 2, 1973 | economic, help, americans, working, programs |
| 182 | Richard Nixon | January 30, 1974 | program, americans, today, energy, tonight |
| 183 | Gerald R. Ford | January 15, 1975 | program, percent, billion, programs, energy |
| 184 | Gerald R. Ford | January 19, 1976 | federal, americans, budget, jobs, programs |
| 185 | Gerald R. Ford | January 12, 1977 | programs, today, percent, jobs, energy |
| 186 | Jimmy Carter | January 19, 1978 | cannot, economic, tonight, jobs, it's |
| 187 | Jimmy Carter | January 25, 1979 | cannot, budget, tonight, americans, it's |
| 188 | Jimmy Carter | January 21, 1980 | help, america, energy, tonight, it's |
| 189 | Jimmy Carter | January 16, 1981 | percent, economic, energy, program, programs |
| 190 | Ronald Reagan | January 26, 1982 | jobs, help, program, billion, programs |
| 191 | Ronald Reagan | January 25, 1983 | problems, programs, americans, economic, percent |
| 192 | Ronald Reagan | January 25, 1984 | budget, help, americans, tonight, it's |
| 193 | Ronald Reagan | February 6, 1985 | help, tax, jobs, tonight, it's |
| 194 | Ronald Reagan | February 4, 1986 | america, cannot, it's, budget, tonight |
| 195 | Ronald Reagan | January 27, 1987 | percent, let, budget, tonight, it's |
| 196 | Ronald Reagan | January 25, 1988 | let, americans, it's, budget, tonight |
| 197 | George H.W. Bush | February 9, 1989 | help, ask, it's, budget, tonight |
| 198 | George H.W. Bush | January 31, 1990 | percent, budget, today, tonight, it's |
| 199 | George H.W. Bush | January 29, 1991 | jobs, budget, americans, know, tonight |
| 200 | George H.W. Bush | January 28, 1992 | know, get, tonight, help, it's |
| 201 | William J. Clinton | February 17, 1993 | tax, budget, percent, tonight, jobs |
| 202 | William J. Clinton | January 25, 1994 | americans, it's, health, get, jobs |
| 203 | William J. Clinton | January 24, 1995 | jobs, americans, get, tonight, it's |
| 204 | William J. Clinton | January 23, 1996 | tonight, families, working, americans, children |
| 205 | William J. Clinton | February 4, 1997 | america, children, budget, americans, tonight |
| 206 | William J. Clinton | January 27, 1998 | ask, americans, children, help, tonight |
| 207 | William J. Clinton | January 19, 1999 | children, budget, help, americans, tonight |
| 208 | William J. Clinton | January 27, 2000 | families, help, children, americans, tonight |
| 209 | George W. Bush | February 27, 2001 | help, tax, percent, tonight, budget |
| 210 | George W. Bush | September 20, 2001 | freedom, america, ask, americans, tonight |
| 211 | George W. Bush | January 29, 2002 | americans, budget, tonight, america, jobs |
| 212 | George W. Bush | January 28, 2003 | america, help, million, americans, tonight |
| 213 | George W. Bush | January 20, 2004 | children, america, americans, help, tonight |
| 214 | George W. Bush | February 2, 2005 | freedom, tonight, help, social, americans |
| 215 | George W. Bush | January 31, 2006 | reform, jobs, americans, america, tonight |
| 216 | George W. Bush | January 23, 2007 | children, health, americans, tonight, help |
| 217 | George W. Bush | January 29, 2008 | america, americans, trust, tonight, help |
| 218 | Barack Obama | February 24, 2009 | know, budget, jobs, tonight, it's |
| 219 | Barack Obama | January 27, 2010 | get, tonight, americans, jobs, it's |
| 220 | Barack Obama | January 25, 2011 | percent, get, tonight, jobs, it's |
| 221 | Barack Obama | January 24, 2012 | americans, tonight, get, it's, jobs |
| 222 | Barack Obama | February 12, 2013 | families, it's, get, tonight, jobs |
| 223 | Barack Obama | January 28, 2014 | get, tonight, help, it's, jobs |
| 224 | Barack Obama | January 20, 2015 | families, americans, tonight, jobs, it's |
| 225 | Barack Obama | January 12, 2016 | tonight, jobs, americans, get, it's |
| 226 | Donald J. Trump | February 27, 2017 | america, jobs, americans, it's, tonight |
| 227 | Donald J. Trump | January 30, 2018 | tax, get, it's, americans, tonight |
| 228 | Donald J. Trump | February 5, 2019 | get, jobs, americans, it's, tonight |
| 229 | Donald J. Trump | February 4, 2020 | jobs, it's, americans, percent, tonight |
| 230 | Joseph R. Biden Jr. | April 28, 2021 | get, americans, percent, jobs, it's |
| 231 | Joseph R. Biden Jr. | March 1, 2022 | let, jobs, americans, get, tonight |
| 232 | Joseph R. Biden Jr. | February 7, 2023 | down, percent, jobs, tonight, it's |
Aside: What if we remove the $\log$ from $\text{idf}(t)$?¶
Let's try it and see what happens.
tfidf_nl_dict = {}
tf_denom = speeches_df['contents'].str.split().str.len()
for word in tqdm(unique_words):
re_pat = fr' {word} ' # Imperfect pattern for speed.
tf = speeches_df['contents'].str.count(re_pat) / tf_denom
idf_nl = len(speeches_df) / speeches_df['contents'].str.contains(re_pat).sum()
tfidf_nl_dict[word] = tf * idf_nl
tfidf_nl = pd.DataFrame(tfidf_nl_dict)
tfidf_nl.head()
keywords_nl = tfidf_nl.apply(five_largest, axis=1)
keywords_nl_df = pd.concat([
speeches_df['president'],
speeches_df['date'],
keywords_nl
], axis=1)
keywords_nl_df
The role of $\log$ in $\text{idf}(t)$¶
$$ \begin{align*} \text{tfidf}(t, d) &= \text{tf}(t, d) \cdot \text{idf}(t) \\\ &= \frac{\text{\# of occurrences of $t$ in $d$}}{\text{total \# of words in $d$}} \cdot \log \left(\frac{\text{total \# of documents}}{\text{\# of documents in which $t$ appears}} \right) \end{align*} $$
- Remember, for any positive input $x$, $\log(x)$ is (much) smaller than $x$.
- In $\text{idf}(t)$, the $\log$ "dampens" the impact of the ratio $\frac{\text{\# documents}}{\text{\# documents with $t$}}$.
- If a word is very common, the ratio will be close to 1. The log of the ratio will be close to 0.
(1000 / 999)
np.log(1000 / 999)
- If a word is very common (e.g. 'the'), removing the log multiplies the statistic by a large factor.
- If a word is very rare, the ratio will be very large. However, for instance, a word being seen in 2 out of 50 documents is not very different than being seen in 2 out of 500 documents (it is very rare in both cases), and so $\text{idf}(t)$ should be similar in both cases.
(50 / 2)
(500 / 2)
np.log(50 / 2)
np.log(500 / 2)
Question 🤔 (Answer at dsc80.com/q)
Code: tfidf
From the Fa23 final: Consider the following corpus:
Document number Content
1 yesterday rainy today sunny
2 yesterday sunny today sunny
3 today rainy yesterday today
4 yesterday yesterday today today
Which words have a TF-IDF score of 0 for all four documents?
Summary, next time¶
Summary¶
- One way to turn documents, like
'deputy fire chief', into feature vectors, is to count the number of occurrences of each word in the document, ignoring order. This is done using the bag of words model. - To measure the similarity of two documents under the bag of words model, compute the cosine similarity of their two word vectors.
- Term frequency-inverse document frequency (TF-IDF) is a statistic that tries to quantify how important a word (term) is to a document. It balances:
- how often a word appears in a particular document, $\text{tf}(t, d)$, with
- how often a word appears across documents, $\text{idf}(t)$.
- For a given document, the word with the highest TF-IDF is thought to "best summarize" that document.
Next time¶
Modeling and feature engineering.